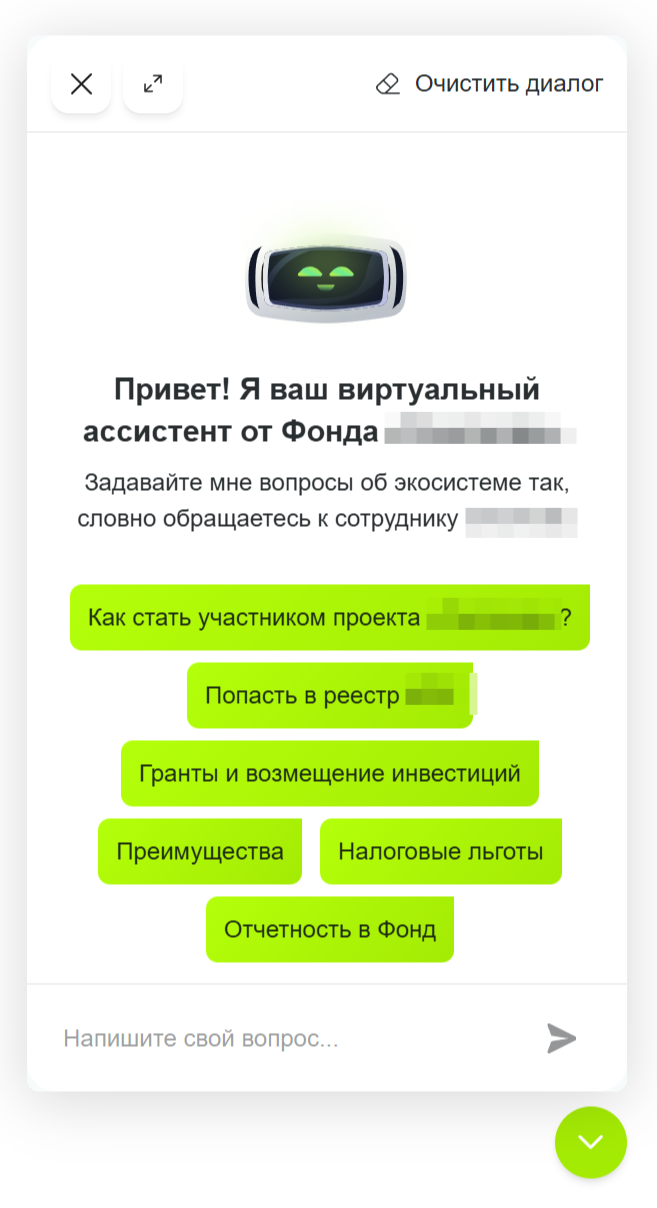
AI-ассистент для сайта и личного кабинета крупного инновационного центра
Создали интеллектуального ИИ-ассистента для сайта и личного кабинета на базе LLM с RAG-архитектурой. Он способен вести контекстный диалог с пользователем, искать ответы в официальных источниках, учитывать приоритет базы знаний AutoFAQ и перенаправлять обращения операторам при необходимости.
О проекте
Клиент — один из крупнейших инновационных центров России, а также экосистема поддержки инноваций, объединяющая стартапы, технологические компании, экспертов, менторов и жителей инновационного центра
Подходит для:
Госсектора / Госуслуг / Институтов развития / EdTech / Финансового сектора / Техподдержки / B2B-порталов / Управляющих компаний / Здравоохранения / Сервисных порталов
Возможности
-

Единая точка входа 24/7
Один AI-ассистент для сайта и личного кабинета, который закрывает поток типовых вопросов и разгружает поддержку.
-

Достоверные ответы из базы знаний
Поиск и генерация только на базе официальных документов, контента и корпоративной базы знаний.
-

Автоматическая маршрутизация обращений
Определение интента, сбор контекста/Service Desk уже с пакетом данных.
-

Контекстный диалог вместо поиска по сайту
Ассистент уточняет детали, удерживает контекст и ведёт пользователя к ответу/действию быстрее и точнее.
-

Персонализация для авторизованных пользователей
Разные сценарии и ответы по роли/статусу пользователя в личном кабинете.
-
Управление и аналитика без разработчиков
Админ-панель для базы знаний, мониторинга качества, истории диалогов и анализа тем/эскалаций.
Цель
Создать и внедрить AI-ассистента как единую интеллектуальную точку входа в поддержку для сайта и личного кабинета, чтобы ускорить получение информации и повысить качество сервиса при высокой нагрузке.
Задачи
- Автоматизировать обработку типовых запросов и снизить нагрузку на службу поддержки.
- Повысить скорость получения информации и удовлетворённость пользователей.
Интегрировать ассистента с действующей системой поддержки AutoFAQ. - Обеспечить масштабируемую архитектуру с заделом на дальнейшее развитие.
Что сделали
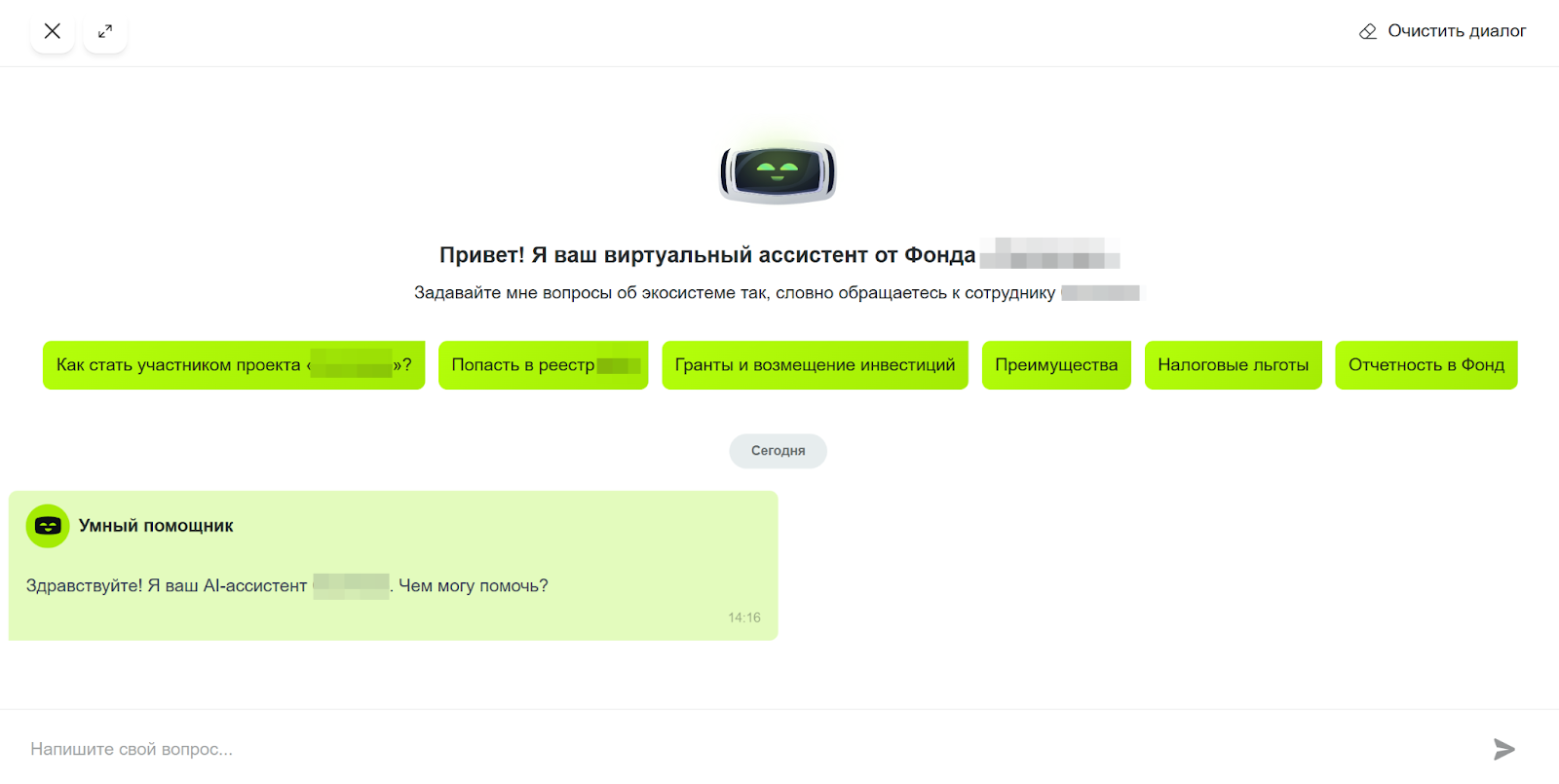
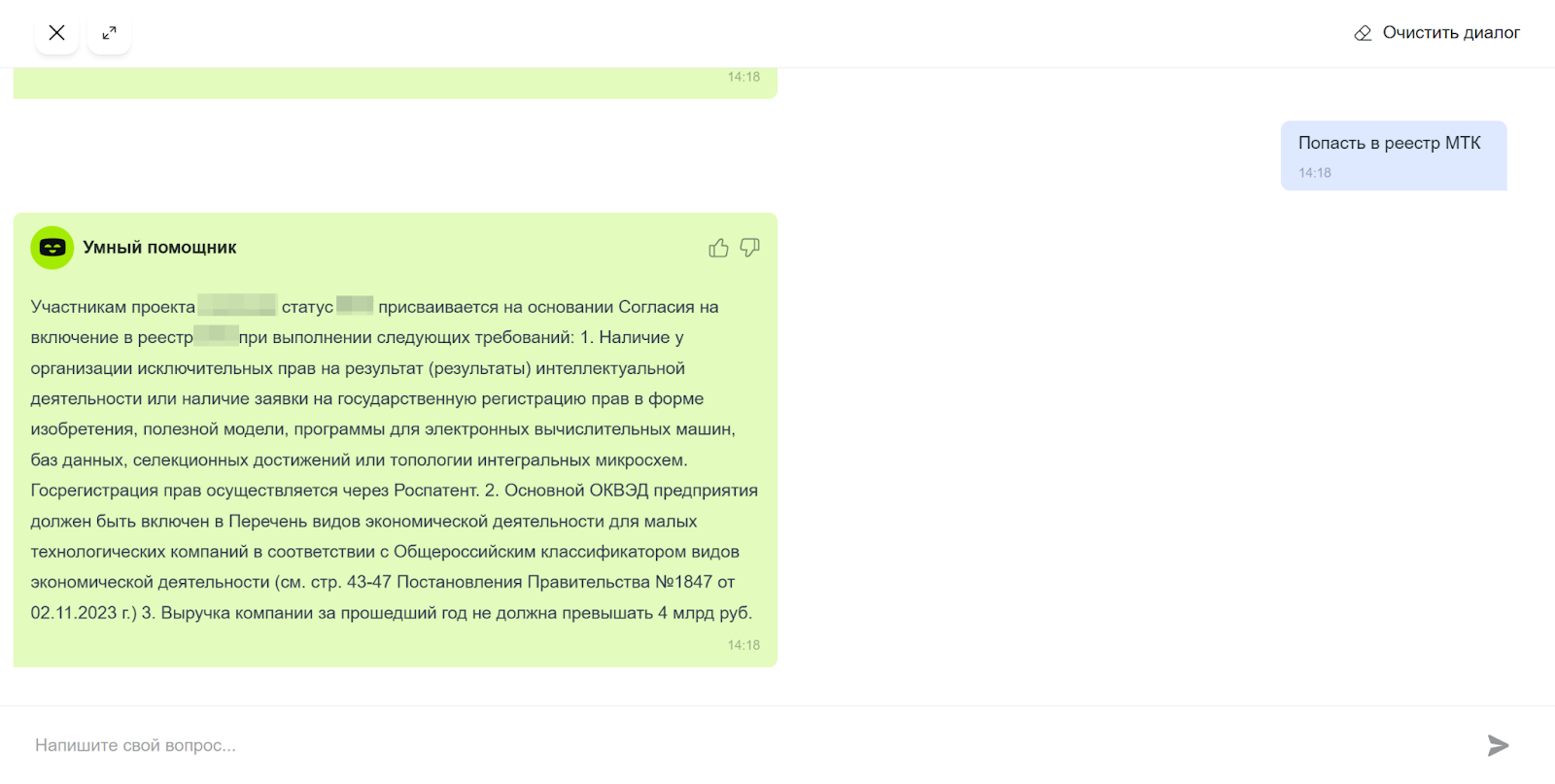
Мы создали AI-ассистента для публичного сайта и личного кабинета — единую интеллектуальную точку входа для разных аудиторий экосистемы: стартапов и инновационных команд, компаний-участников, жителей и гостей территории, а также экспертов и менторов. Ассистент 24/7 отвечает на типовые вопросы по статусу участника, доступным мерам поддержки и льготам, административным процессам и услугам, инфраструктуре и событиям, работе с заявками и выплатами.
Он ищет ответы в большом массиве разрозненных официальных документов и регламентов, собранных из разных источников, учитывает базу знаний AutoFAQ, что позволяет структурировать информацию, снизить нагрузку на поддержку и ускорить получение ответов для пользователей.
AI-ассистент работает на базе LLM с RAG-архитектурой. Он способен:
● вести контекстный диалог с пользователем;
● искать ответы в официальных источниках;
● учитывать приоритет базы знаний AutoFAQ.
Этапы проекта
#1 Проектирование сценариев и требований
-
Определили ключевые пользовательские сегменты и интенты для сайта и личного кабинета, зафиксировали типовые запросы и правила, по которым обращения должны эскалироваться к операторам (Human-in-the-Loop).
#2 Подготовка базы знаний и источников данных
-
Подключили приоритетный источник — базу знаний AutoFAQ, дополнительно собрали и структурировали официальные документы Фонда, контент сайта sk.ru и его поддоменов, а также новости и события для обеспечения достоверных ответов.
#3 Разработка интеллектуального ядра (LLM + RAG)
-
Реализовали AI-ассистента на базе LLM с RAG-архитектурой: он ведёт контекстный диалог, ищет ответы в официальных источниках, учитывает приоритет AutoFAQ и при необходимости перенаправляет запрос оператору.
#4 Построение масштабируемой архитектуры
-
Спроектировали и внедрили асинхронную микросервисную архитектуру с очередями задач и масштабируемыми воркерами, развернули компоненты LLM Platform, RAG-пайплайн, Qdrant (векторная база), PostgreSQL (диалоги и аналитика), Redis + BullMQ (асинхронная обработка) и интеграцию с AutoFAQ.
#5 Интеграция в каналы и UX
-
Встроили ассистента в публичный сайт и личный кабинет как кастомизируемый чат-виджет, добавили быстрые кнопки и подсказки, адаптацию под мобильные устройства, персонализацию для авторизованных пользователей и единый официальный тон общения.
#6 Администрирование и аналитика
-
Создали административную панель для просмотра истории диалогов, управления базой знаний, мониторинга качества, аналитики активности и вовлечённости, а также настройки ассистента без участия разработчиков; настроили логирование всех обращений для постоянного улучшения.
#7 Тестирование и контроль качества
-
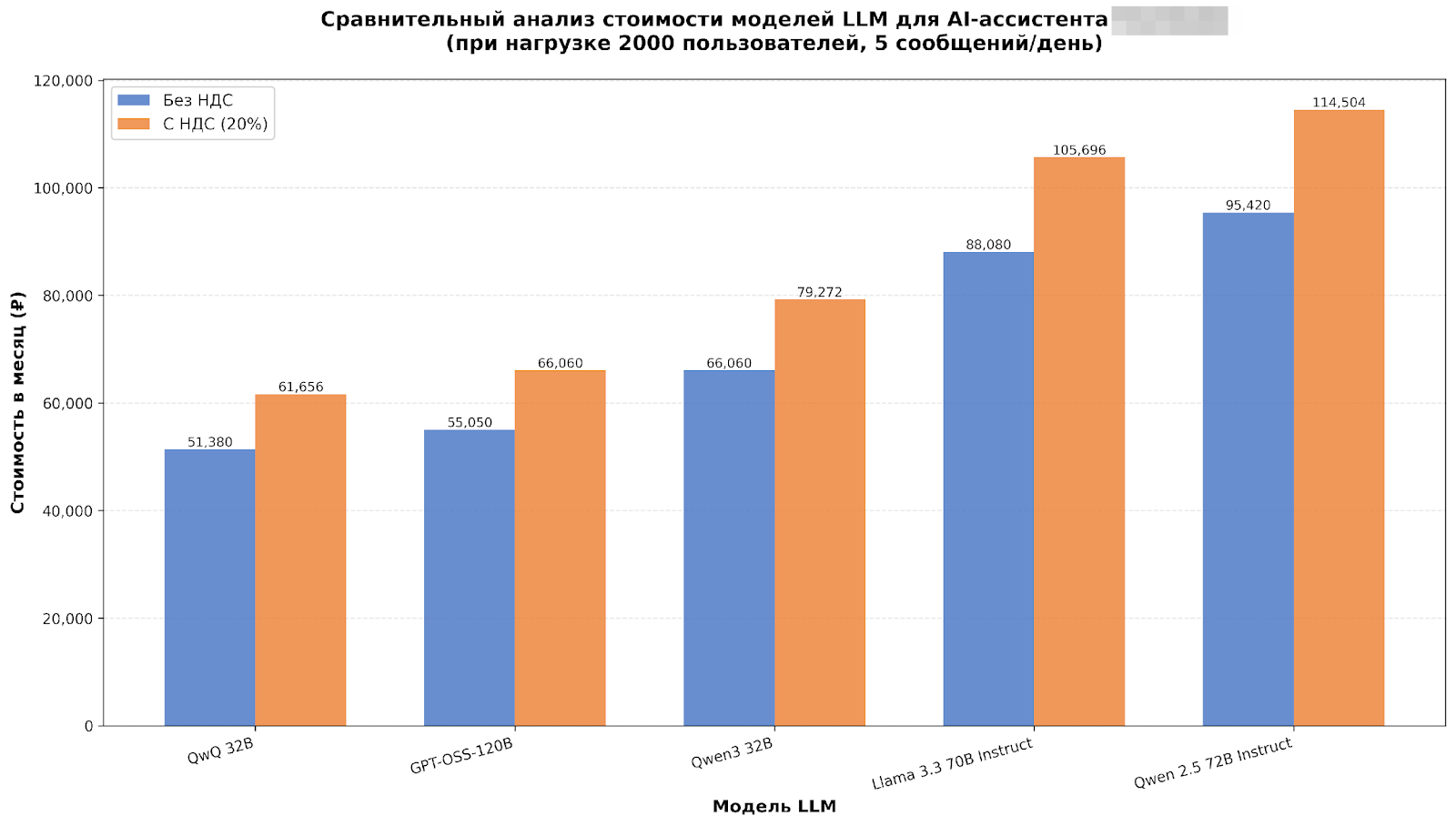
Мы провели сравнительное тестирование LLM для AI-ассистента, чтобы выбрать оптимальную модель при требовании не ниже 70% точности на типовых пользовательских запросах.
-
Для этого мы протестировали 5 больших языковых моделей на 20 тестовых кейсах, покрывающих ключевые сегменты целевой аудитории. Система тестирования была построена на базе встроенного функционала LLM-платформы и включала Datasets (наборы входных запросов и эталонных ответов), Evaluators (автоматизированные критерии оценки: RAGAS + LLM-as-a-Judge на GPT-4.1) и Analytics Dashboard для мониторинга результатов и визуализации метрик.
-
Дополнительно мы рассчитали ежемесячную стоимость эксплуатации каждой модели и подтвердили, что использование GPT-OSS-120B обеспечивает экономически обоснованные операционные расходы.
-
По итогам оценки качества, стабильности и стоимости владения для промышленной эксплуатации была выбрана модель Cotype 2 Pro от MTS AI. Модель продемонстрировала 87,8% Accuracy, что на 17,8 п.п. превышает целевой порог, и показала наилучший баланс между точностью, предсказуемостью ответов и операционными расходами.
-
Cotype 2 Pro особенно уверенно работает с ключевыми типами обращений — информационными (93,8%) и процедурными (83,3%) запросами, которые формируют около 70% всего пользовательского потока, обеспечивая стабильные и достоверные ответы в режиме 24/7 при высокой нагрузке.
Stack
Асинхронная микросервисная архитектура с очередями задач и масштабируемыми воркерами
| Слой / Компонент | Инструменты и сервисы |
|---|---|
| Управление LLM и логика обработки запросов |
LLM Platform
|
| RAG-пайплайн и поиск релевантных данных |
RAG-пайплайн
|
| Векторное хранилище и эмбеддинги |
Qdrant — векторная база эмбеддингов
|
| Хранилище данных и аналитика |
PostgreSQL
|
| Очереди и асинхронная обработка |
Redis + BullMQ
|
| Интеграция со службой поддержки |
AutoFAQ
|
Результаты и аналитика
| Результаты |
|---|
| Стабильная работа под высокой нагрузкой |
| Существенно снижена нагрузка на службу поддержки |
| Повышена доступность и прозрачность информации для пользователей |
| Повышена доступность и прозрачность информации для пользователей |
| Метрика | СТАЛО |
|---|---|
| Точность ответов | 87,8% |
| Частота ошибок | 15% |
| Время ответа | до 10 секунд |
Со стороны OSMI IT проект вели
АД
Анастасия Дермичева
CBDO OSMI IT
ДН
Денис Нагаев
CTO OSMI IT
АШ
Артём Ш.
Менеджер проекта
ЭМ
Элмурат М.
LLM-разработчик
ПЧ
Павел Ч.
Back-end разработчик
ВК
Владимир К.
DevOps-инженер
АК
Алиса К.
QA-инженер